Onboard Perception and Navigablity Leanring
Effective perception is crucial for enabling robots to interact seamlessly with their environments. Our research on perception focuses on developing innovative sensing representations that enhance how robots perceive and understand the world around them. We work on two types of sensors: ransing sensors such as LiDAR and RADAR, and visual sensors such as monocular cameras.
Geometric Representation and Learning

3D LiDARs and other high-definition ranging sensors have long been crucial for autonomous systems, enabling them to navigate and map structured environments like indoor spaces and highways. However, these technologies are less frequently employed in robot navigation and exploration in highly unstructured environments, such as crop fields or dense forests, where numerous small, indistinguishable objects present challenges. In fact, navigating such environments is difficult even for humans. Imagine needing to cross an unfamiliar forest without any defined paths. We typically identify navigable areas by recognizing open spaces amidst random vegetation. In this context, obstacles like clusters of shrubs are grouped together, and navigation decisions are made by selecting a clear passage.
We have designed a novel framework that integrates key autonomy components—perception, navigation, and mapping—by using an abstracted approach suited for complex unstructured environments, such as forest trails. Our framework is based on Gaussian processes, which model local perception, assess the quality of global exploration, and guide the mapping of navigable spaces. This representation reduces sensitivity to small, irrelevant objects, enabling the robot to identify navigable passages in noisy, dynamic environments. Moreover, it allows the robot to adaptively construct a lightweight map that accurately reflects environmental navigability, ensuring comprehensive spatial coverage while maintaining computational efficiency.
Specifically, we utilize a Sparse Gaussian Process (SGP) to model the local depth perception of 3D occupied points. This approach allows us to correlate points within a neighborhood, moving beyond the traditional independence assumption prevalent in existing occupancy representation frameworks. By doing so, we not only improve the accuracy of the perception model but also incorporate uncertainty assessments, which are essential for reliable navigation.
One of the key insights from our work is that the uncertainty inherent in our model can be leveraged to sketch spatial navigability, enabling the identification of navigation guidance frontiers with remarkable ease. This framework illustrates how local perception can naturally facilitate local navigation, laying the groundwork for more complex robotic behaviors. Moreover, it reveals that navigation, mapping, and exploration can all be derived from a unified foundation based on Gaussian processes, thereby streamlining the processes involved in robotic perception.

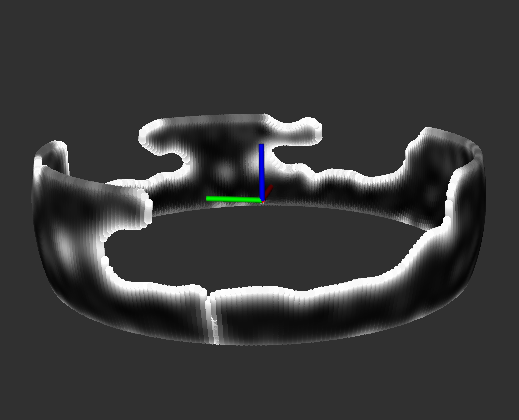

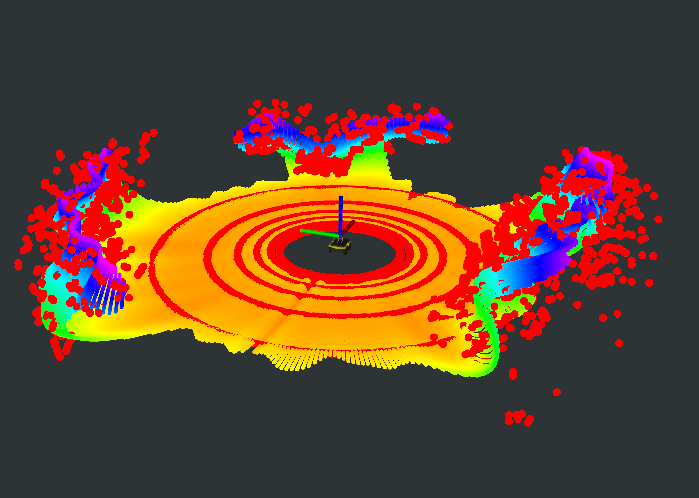
The SGP occupancy model as a local 3D map. (a) Variance (uncertainty) surface associated with the SGP occupancy model; (b) Variance surface after removing high variance regions; (c) SGP occupancy model (outer surface) compared with the original occupancy (inner surface). Warmer colors indicate higher occupancy values; (d) Reconstructed pointcloud from the SGP occupancy model (rainbow-colored, where color represents z-axis) versus the raw pointcloud.
YouTube link:
Navigable Space Segmentation for Autonomous Visual Navigation:
In addition to the depth and the underlying geometric modeling, our research extends to semantic embedding, particularly in scenarios where data availability is limited, such as navigating through dense forest trails. The ability to predict traversability in unfamiliar scenes is vital for the success of autonomous navigation. To tackle this, we focus on adapting perception models for high data efficiency, which not only minimizes the need for costly data labeling but also enhances generalization across diverse environments. A significant challenge we encounter is the domain shift between source and target environments— for instance, transitioning from freeway driving to forest navigation. To address this, we propose novel coarse-to-fine unsupervised domain adaptation (UDA) models. Our innovative approach combines coarse and fine alignment processes to create efficient UDA models that maintain stable training. We have rigorously tested our methodology, demonstrating its superiority over baseline models in various domain adaptation scenarios and making it more robust and adaptable to the complexities of real-world environments.


Left: We use the Intel T265 for localization and the Intel RealSense D435i for computing the surface normal images which are the inputs to our perception model.. Right: Different visual information may provide information on different aspects of the surrounding environment. .
YouTube link:
YouTube link: